Resumo
Redes Ethernet industriais seguem liderando novas instalações e modernizações, com PROFINET concentrando grande parte dos projetos, especialmente onde disponibilidade e determinismo são mandatórios. Nesse contexto, a robustez de uma rede PROFINET não depende apenas de projeto e comissionamento, ela depende de evidência contínua de saúde operacional.
Na prática, falhas raramente surgem sem sinais prévios. Antes do alarme de comunicação, aparecem tendências mensuráveis, como crescimento de jitter, aumento de netload, ocorrências de cycle fault, overtakes e, por fim, dropped no tráfego cíclico RT. O problema comercial por trás disso é direto: quando a planta reage apenas no evento, o MTTR cresce, o risco de paradas não programadas aumenta e o custo de intervenção se torna maior do que o custo de prevenção.
Este artigo apresenta uma abordagem completa de monitoramento, combinando captura passiva, via sniffer com TAP, e diagnósticos ativos, via leitura de estatísticas, topologia e saúde de portas e dispositivos, por exemplo via SNMP. Ao final, descreve uma aplicação típica com o TS Monitor PROFINET SNIFFER, que consolida monitoramento passivo e ativo e suporta PROFINET S1 e S2 em um único hardware, ponto relevante para arquiteturas redundantes e plantas de alta disponibilidade.
Glossário prático: métricas que serão abordadas.
Antes de entrar nos detalhes, seguem os termos que serão usados ao longo do texto:
– IO Cycle: tempo de atualização cíclica por IO Device (base do desempenho do controle).
– Jitter: variação do tempo de chegada dos telegramas em relação ao ciclo nominal; principal indicador de tendência.
– Dropped: perda efetiva no ciclo cíclico de I/O (impacto direto no controle).
– Overtake: telegramas fora de ordem (sinal de anomalia; exige investigação dirigida).
– Cycle fault: pacotes atrasados acima de um limite (por exemplo, jitter > 100% do ciclo).
– Netload: carga de rede e sua composição (controle vs tráfego externo).
1 – O que realmente degrada uma rede PROFINET
Em campo, é comum atribuir falhas de rede a explicações genéricas (“partida de motor”, “interferência”, “mudança de carga”). Para a rede PROFINET, essas hipóteses só fazem sentido quando são comprovadas por evidências de camada física e de switch: erros de porta, eventos de link, descartes, crescimento de jitter e perdas no tráfego cíclico. Sem medição, o diagnóstico vira tentativa e erro.
A degradação costuma aparecer em três frentes:
1.1 Degradação por camada física e montagem
A origem mais frequente está em detalhes “simples”, porém críticos: conectores mal montados, blindagem inadequada, raio de curvatura excedido, danos mecânicos, umidade/ingresso de água ou componentes fora de especificação. O efeito típico é gradual e observável:
– Aumento de erros/descartes em portas;
– Perdas intermitentes;}
– Jitter crescente (instabilidade do ciclo);
– Link flaps (oscilações de link).
Em redes PROFINET, pequenos desvios na camada física tendem a se traduzir primeiro em instabilidade temporal (jitter) e, em seguida, em perdas efetivas de pacotes.
1.2 Degradação por tráfego e filas de switch
PROFINET cíclico (RT) depende de previsibilidade. Quando a rede opera perto do limite, ou quando surgem microcongestionamentos, aumenta a variação de latência — observada como jitter. Se o problema continuar, o próximo degrau é o packet dropping nos buffers dos switches.
Aqui está o ponto de valor do monitoramento: tendência de jitter/netload permite avaliação de risco e risco e planejamento de ação antes do evento afetar o processo.
1.3 Degradação por configuração, topologia e manutenção
A terceira frente é menos “visível” e costuma consumir mais tempo de equipe: mudanças de topologia, comportamento inesperado de redundância (MRP/MRPD), inconsistências de engenharia, velocidade/duplex, anomalias em broadcast/multicast (ARP/DCP), entre outras. Nesse conjunto, o monitoramento ativo é decisivo: ele aponta onde o problema está (porta/dispositivo/topologia), enquanto o passivo mostra como isso se manifesta nos pacotes e quem está sendo impactado.
2 – Detectar tendência é melhor do que “pegar a falha”
O erro estratégico em manutenção de redes industriais é esperar um evento “catastrófico” para agir. Em muitos casos, ocorre a falha, busca o analisador e vai para campo realizar análise de falha. O caminho tecnicamente consistente é monitorar tendência e tratar degradação como fenômeno progressivo. Uma sequência típica em incidentes reais é:
– Netload sobe ao longo de semanas (novos nós/serviços, tráfego indevido, mudanças de engenharia);
– Jitter cresce (primeiro sintoma mensurável);
– Surgem cycle faults e overtakes em condições específicas;
– Aparece dropped e, finalmente, perda de conexão/alarme de comunicação.
Ou seja: quando “a rede cai”, normalmente ela já estava “avisando” — desde que alguém estivesse medindo.
3 – Monitoramento completo: passivo + ativo
3.1 Monitoramento passivo — por que TAP é a escolha robusta
Monitoramento passivo é observar fluxos sem gerar tráfego adicional, sem alterar o comportamento da rede e o melhor, sem depender da resposta de dispositivos sobrecarregados. Há duas abordagens comuns:
a) Espelhamento de porta (port mirroring / SPAN)
É prático e útil, especialmente para troubleshooting. Porém, tem limitações estruturais que o tornam frágil como “sensor” permanente:
– A porta espelho tem limite de taxa: TX+RX da porta monitorada pode exceder a capacidade do espelho → perda da cópia e até falha no switch;
– Switches podem ter rate-limit ou descartar tráfego espelhado em picos;
– Dependendo do equipamento, pode haver variação significativa de temporização na cópia, reduzindo confiabilidade para análises finas (por exemplo, jitter).
Por isso, espelhamento é indicado para testes pontuais, não como base de monitoramento contínuo quando se busca precisão e cobertura total.
b) TAP (Test Access Point)
O TAP, inserido no link, entrega uma cópia fidedigna do tráfego e tipicamente com robustez superior para observação contínua:
– Melhor confiabilidade para captura permanente;
– Visibilidade consistente de fluxos críticos de controle;
– Base adequada para auditoria técnica e correlação temporal (tendência/ocorrência);
– Opções a prova de falha.
É nesse desenho que o TS Monitor PROFINET SNIFFER se encaixa: ele captura e interpreta pacotes de controle de forma passiva (sniffer/TAP) e calcula as métricas como jitter, dropped, overtake e netload.

3.2 Monitoramento ativo — o que o passivo não substitui
Monitoramento ativo é consultar componentes (switches e dispositivos) para extrair diagnósticos, estado e contadores. Ele é indispensável para reduzir MTTR porque aponta onde investigar primeiro, por exemplo:
– Portas com erros/descartes e mudanças de estado;
– Consistência de topologia (vizinhança) e eventos de rede;
– Saúde de protocolos de redundância (por exemplo, estado de anel);
– Crescimento de contadores “silenciosos” (a rede ainda comunica, mas já está degradando).
Além disso, indicadores quantitativos como pacotes perdidos obtidos via SNMP entregam evidência rastreável por porta — ideal para correlação objetiva com jitter, netload e eventos.
4 – Indicadores que realmente “enxergam” degradação
4.1 Netload
Netload é o “termômetro” da ocupação da rede. Aumentos sustentados ou picos recorrentes indicam risco de congestionamento. O ideal é separar PNIO vs. não-PNIO e enxergar IN/OUT, porque isso mostra se a pressão vem do tráfego de controle ou de tráfego externo (TI, serviços diversos, varreduras, etc.).
4.2 Perda de pacotes (via SNMP)
Em redes PROFINET, perda de pacotes deve ser tratado como métrica quantitativa, obtida preferencialmente por contadores de porta lidos via SNMP em switches gerenciáveis. O valor mais útil é o incremento, pois permite:
– Medir severidade;
– Correlacionar com horários de instabilidade e intervenções;
– Comparar segmentos e portas para localizar o foco.
Na prática, a perda de pacotes detectada por SNMP representa perdas/descartes no nível Ethernet (por exemplo, quadros com erro e descartes por fila), conforme o fabricante expõe os contadores. Por isso, o ganho está em padronizar baseline e regras de alarme — e usar o indicador como evidência para planejamento de ações.
4.3 Dropped (no ciclo RT)
Em PROFINET cíclico, dropped é o indicador mais “duro”: significa que um pacote não chegou. Dropped tem ligação direta com desempenho do controle e deve disparar ação imediata (mitigar causa, reduzir tráfego indevido, corrigir infraestrutura, isolar origem).
4.4 Jitter
Jitter é a variação do tempo real entre telegramas consecutivos em relação ao ciclo configurado. É o melhor indicador de tendência porque cresce quando:
– A rede se aproxima do limite (filas variam);
– Há microcongestionamentos;
– Surgem instabilidades físicas e de switching.
Interpretação prática:
– Netload alto + Jitter alto → risco de congestionamento e degradação progressiva.
– Jitter alto sem Netload alto → investigar instabilidade física, priorização/filas, topologia e portas degradadas.
– Dropped após jitter → rede entrou em regime de falha (ação imediata).
4.5 Overtake
– Overtake indica pacotes fora de ordem. Em redes industriais, é um gatilho útil para investigação dirigida (fenômenos de fila/caminho/condições anormais).
4.6 Cycle fault
– Cycle fault classifica pacotes atrasados acima de um limite (por exemplo, jitter > 100% do ciclo) e funciona como ponte entre tendência (jitter) e falha (dropped).
5 – Infraestrutura: por que cabeamento pronto, injetado e certificado reduz risco
A camada física é onde mais se “economiza errado”. Cabos montados em campo exigem ferramental, treinamento e controle de qualidade. Em contraste, cabos pré-montados/injetados e certificados de fábrica reduzem:
– Erros de montagem de conector;
– Problemas de blindagem e continuidade;
– Variabilidade por instalador;
– Retrabalho e falhas intermitentes difíceis de reproduzir.
Em PROFINET, isso tem impacto direto porque instabilidades pequenas viram jitter e, depois, dropped — e o custo do downtime tende a superar o custo marginal de padronização.
Obs: switches fazem parte importante e, neste contexto, switches PROFINET com diagnóstico, interfaces Gigabit e gerenciáveis podem ser a diferença entre o sucesso e o fracasso no diagnóstico e robustez.
6 – Redundância PROFINET S2: por que monitorar fica mais complexo
Em arquiteturas com Redudância de Sistema S2, o dispositivo mantém relação ativa com um controlador e relação de backup em standby, habilitando troca quase sem interrupção quando há falha no IO Controller ou do caminho/controlador ativo. Isso eleva disponibilidade, mas torna o diagnóstico mais sofisticado: é necessário enxergar tráfego, eventos e tendências associados aos dois caminhos e às transições.
O TS Monitor PROFINET SNIFFER atende PROFINET S2 em um único hardware, evitando múltiplas ferramentas e permitindo visibilidade contínua — ponto relevante em plantas que requerem alta disponibilidade.
7 – Aplicação típica com o TS Monitor PROFINET SNIFFER
7.1 Objetivo
Implementar monitoramento contínuo para:
– Criar baseline do comportamento normal (por segmento/célula/controlador);
– Detectar tendência antes de falha (jitter/netload/pacotes perdidos);
– Reduzir mttr quando a falha ocorre (evidência objetiva e localização mais rápida);
– Produzir evidência técnica (relatórios/eventos) para gestão e auditoria.
7.2 Arquitetura recomendada (passivo + ativo)
Inserir o TS Monitor PROFINET SNIFFER no mesmo painel do IO Controller e conectar os cabos PROFINET passando pelo TAP do equipamento. Em outro ponto conectar o cabo para a comunicação ativa do sistema de monitoramento. A figura abaixo mostra a conexão em sistema S2.
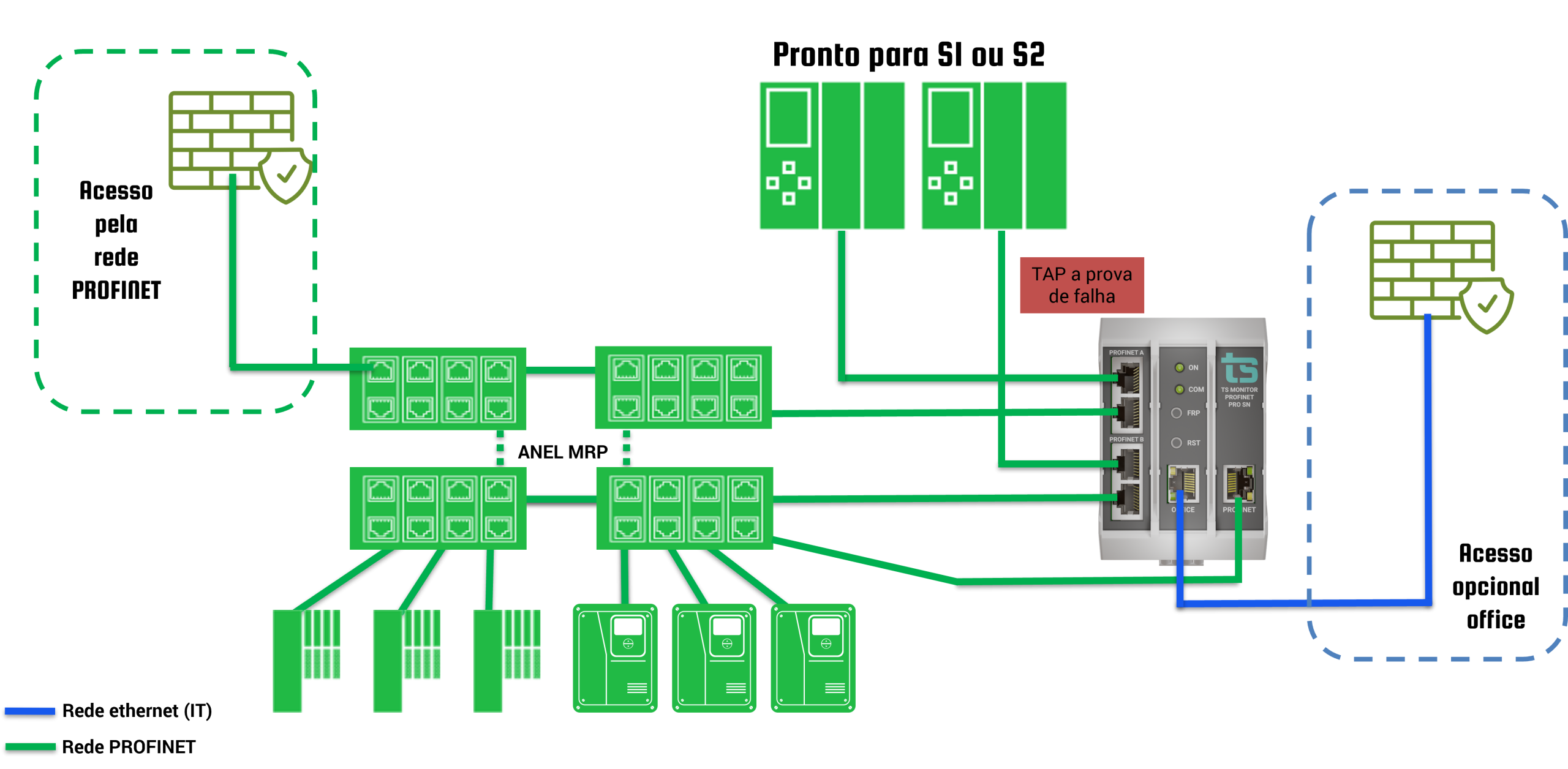
Pontos importantes:
– Monitor ao ponto de observação passiva para captura integral de pacotes de controle.
– Habilitar diagnósticos ativos em switches e dispositivos (quando aplicável) para coletar contadores, topologia e status.
7.3 O que o TS Monitor entrega “a mais” na prática
O ganho não é “ver pacotes”: é reduzir o ciclo suspeita → tentativa → erro e migrar para um modelo orientado a evidência:
– Preditivo: baseline + tendência (jitter/netload) antes do evento.
– Quantitativo: pacotes perdidos via SNMP com valor rastreável por janela.
– Direto no controle: dropped/cycle fault ligados ao PN-IO (impacto real).
– Completo: passivo (pacotes) + ativo (topologia/estatísticas/estado).
– Alta disponibilidade: suporte a S2 em um único equipamento, simplificando o monitoramento em redes redundantes.
Conclusão
Monitorar PROFINET de forma consistente significa abandonar diagnóstico puramente reativo e adotar um modelo técnico e mensurável: medir tendência, jitter e netload, quantificar perdas por porta via contadores, detectar perda efetiva no ciclo RT, dropped, correlacionar com saúde de rede em diagnósticos ativos e garantir visibilidade de fluxos por captura passiva com TAP.
O TS Monitor PROFINET SNIFFER operacionaliza esse modelo ao consolidar leitura passiva de telegramas de controle e diagnósticos ativos, com suporte a PROFINET S2 em um único hardware, diferencial para plantas que exigem previsibilidade e alta disponibilidade.
Essa novidade estará disponível a partir de junho de 2026. Agende uma demonstração online para validar, com dados da sua própria planta, como baseline de netload e jitter pode antecipar degradação, reduzir MTTR e sustentar decisões de correção com evidência.
Telefone: +55 (16) 3419 1577
E-mail: vendas@toledoesouza.com
Referências:
- HMS NETWORKS. Industrial Network Study. Halmstad: HMS Networks, 2023.
- PROFIBUS NUTZERORGANISATION E.V. (PNO). PROFINET Commissioning Guideline. Karlsruhe: PNO, 2022. Order No. 8.082, Version 1.53.
- PROFIBUS NUTZERORGANISATION E.V. (PNO). PROFINET Design Guideline. Karlsruhe: PNO, 2022. Order No. 8.062, Version 1.53.
- PROFIBUS NUTZERORGANISATION E.V. (PNO). PROFINET Assembling Guideline. Karlsruhe: PNO, 2022. Order No. 8.072, Version 2.12.
- PROFIBUS NUTZERORGANISATION E.V. (PNO). PROFINET Planning Redundancy. Karlsruhe: PNO, 2023. Order No. 8.132, Version 1.00.
- CISCO SYSTEMS. SPAN/RSPAN/ERSPAN Configuration Guide. San Jose: Cisco Systems, 2012.
- TS REDES INDUSTRIAIS. Guia do usuário TS Monitor PROFINET PRO SN. Versão 1.0.1. [S.l.]: TS Redes Industriais, s.d.